Apache Spark (https://spark.apache.org/) is one of the most popular analytics engines used nowadays. It has been around since 2009 and one of the reasons it became so popular is its speed compared to traditional MapReduce and specifically Hadoop, which it was inspired by.
There are other reasons that Spark has done so well, but speed, which is achieved by the ability to store intermediate results in memory rather than disk, is one of the first things that comes to most people’s minds.
In this article we will look into some subtle, but very important differences that I discovered when I was working on some ETL pipeline optimizations at work. They caught me by surprise and hopefully sharing this here would help someone out there.
IMPORTANT NOTE: The examples below work exactly as one would expect in Spark 2.4.0. I discovered the issue I wanted to cover in here while the latest version was still 2.3.x and used Spark 2.4.0 for the examples in this article. This way I found out that the issue has been addressed and is no longer something you should be careful with, unless you’re using an older version of Spark.
Resilient Distributed Datasets
Resilient distributed datasets (RDDs) are the main abstraction that Spark provides to represent a collection of elements (data) that can be distributed across the different nodes of a cluster. Spark can operate in parallel over those collections using functional programming concepts like map, flatMap and many more.
RDDs were the main programming interface until Spark 2.0. After that they have been replaced by Datasets, which bring the benefit of more optimizations under the hood. RDDs are still available, but it seems like their usage is mostly discouraged as it requires some deeper understanding and care in order to make Spark perform as fast as possible. However, RDDs are still useful if you know what you’re doing and you really want to be in control of things.
Datasets
From Spark 2.0 onwards, Datasets are the main programming interface for Spark. There are some differences about how they are used, but the main functional concepts are still there and still do the same things.
From RDDs to Datasets
The purpose of this article is not to show how to go from the old interface to the new one. It is generally a straightforward task, but it has its own specifics. In some cases, your code might require some non-trivial refactoring in order to achieve what you had with RDDs using the Dataset interface. In general, however, things are relatively easy.
It is normal that people who have been working with Spark for a long time, would have written lots of RDD-based code. With evolution, you might decide to rewrite some of your pipelines to using Datasets or make sure new pipelines, jobs, etc. use the new interface. This was the case at work:
Initially all our Spark code was based on RDDs. We went through rewriting pretty much everything except 1 or 2 jobs to using Datasets.
Our code was very well optimized. Things were running pretty fast already, but we thought that going to Datasets we can make things run even faster or in the worst case – as fast, but be more in line with the current trends. Using Datasets would also slightly lower the requirements for engineers to really know what they are doing and minimize errors based on lack of experience. This is exactly what we achieved, except a few specific instances we ran into. The most surprising one was related to caching and managing intermediate data in memory for reuse in multiple different branches of some complex jobs. The next few sections will talk about our findings.
Example Setup
All of the examples we will see in this article are using the spark-shell REPL. You can, of course do this in code, but this is the easiest way to test things out. The version of Spark used is 2.4.0. NOTE: The issue covered here does not occur in Spark 2.4.0. It does in 2.3.x.
Persisting RDDs
Persisting RDDs happens using the cache() method that each RDD has. It will put the contents of the RDD in memory and the next time you want to access them, they will be readily available, rather than being read or calculated from a previous available representation.
Let’s consider the following example:
scala> val rddOne = sc.parallelize(Seq(1, 2, 3, 4, 5, 6)).cache()
rddOne: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at :24
scala> rddOne.count()
res2: Long = 6
scala> val rddTwo = rddOne.map(n => n + 1).cache()
rddTwo: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at map at :25
scala> rddTwo.count()
res3: Long = 6Here we create an RDD, cache it, call count() on it to make sure it’s actually in memory, then use it to calculate another RDD and then call count() on the second RDD, which will cause all computations to be executed. If we look at Storage tab in the Spark UI we will see something similar to the following image:
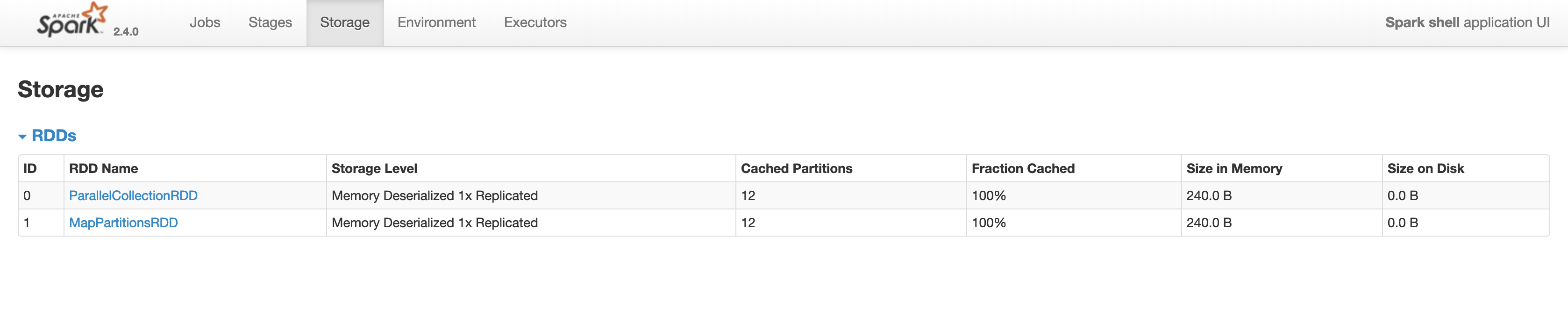
The image above proves that we have 2 RDDs in memory, which is exactly what we expected.
Optimizing Our Example
Imagine that we are working with lots of RDDs and at some point we decide to free up some memory by un-persisting RDDs that we no longer need. We can add the following line to the end of the above example:
scala> rddOne.unpersist()
res4: rddOne.type = ParallelCollectionRDD[3] at parallelize at :24This line will remove rddOne from memory, but will keep rddTwo and we will be able to keep using it for other calculations. The image below proves that – only the mapped RDD remains in the Storage:

If we decide to do some other operations with rddOne, then it will have to be recreated again. In real life application this might mean reading and processing petabytes of data multiple times. That’s why you should only un-persist RDDs when you’re sure you will no longer be needing them. The freed up memory then will be available for you to cache other potential intermediate datasets.
Persisting Datasets
Let’s now look at the same example, but this time using Datasets instead. Here is how the equivalent example will look like:
scala> val datasetOne = spark.createDataset[Int](Seq(1, 2, 3, 4, 5, 6)).cache()
datasetOne: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> datasetOne.count()
res5: Long = 6
scala> val datasetTwo = datasetOne.map(n => n + 1).cache()
datasetTwo: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> datasetTwo.count()
res6: Long = 6The following image shows the Storage tab in the Spark UI, which this time has 2 datasets cached in memory:
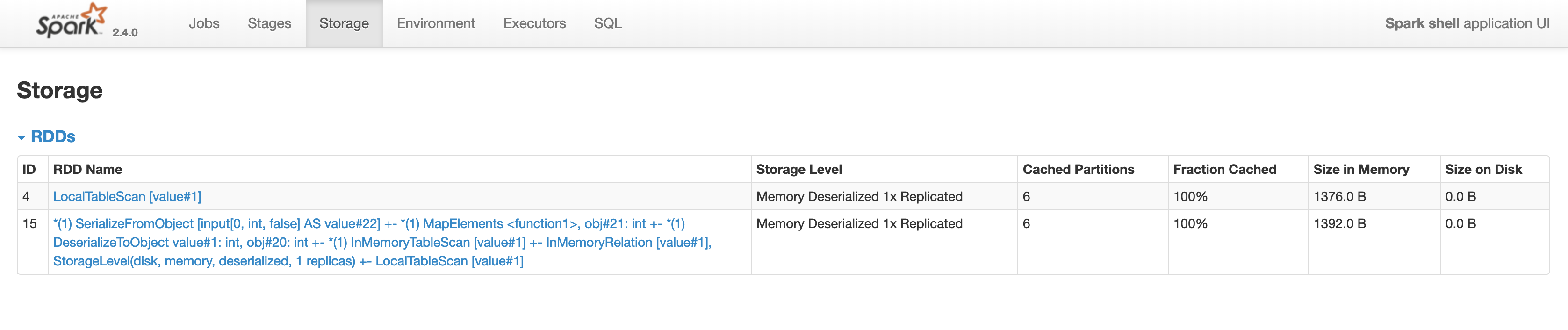
Optimizing the Dataset Example
Let’s now follow the same path as we did with the RDDs and un-persist the first Dataset, assuming that we no longer need it in memory, because it will not be used for any calculations anymore. We issue the following command in the Spark Shell:
scala> datasetOne.unpersist()
res7: datasetOne.type = [value: int]Now, if we look at the storage tab, we will see the following image:

As you can see, the first Dataset disappeared and we only have the second one available.
Optimizing the Dataset Example Prior to Spark 2.4.0
If you run exactly the same example as above, but on an earlier version of Spark, something unexpected will happen. The Storage tab will actually show nothing. This means that:
In Spark versions earlier than 2.4.0, un-persisting a Dataset, which is a dependency of other downstream Datasets, will also un-persist all of the downstream Datasets as well.
Our code had optimizations similar to what’s shown in the examples above. With Spark 2.3.x this actually caused some jobs to take much longer than they did before. The reason for that was that some intermediate Datasets were un-persisted after their last use and after dependent datasets were cached. This was actually causing TBs of data to be re-read multiple times whenever we did multiple aggregations on top of the dependent datasets.
Our solution was to get rid of any explicit calls to unpersist() and let Spark handle them if more free memory is needed. This seemed to work well.
Conclusion
This article shares an experience I had with going from RDDs to Datasets in Spark 2.3.x. Some points that you should take from this are:
- Test your jobs and monitor their performance – this way you can find issues that you didn’t expect to occur.
- Use the REPL to test your hypotheses.
- Be very careful when downgrading Spark versions as things could be quite different and affect your performance negatively.
- Be very careful when upgrading Spark for the same reasons as above.
This article might seem a bit strange and the reason is that it took me a long time to get inspired to sit down and write it down. So long that a new version of Spark was released after I discovered the problem and then while writing it I actually discovered that the problem I wanted to talk about has been addressed in the new version. I still hope you liked it and you learned something useful from it.
Thanks, nice post
Thanks! 🙂